 About
About
That's not "real" scrum: Measuring and managing productivity for development teams
By far, the biggest reason I see scrum failing to deliver is when the ceremonies or ideas or data generated by scrum gets used for something other than delivering value to the end users.
It’s completely understandable! Management broadly wants predictability, the ability to schedule a release months out so that marketing and sales can create content and be ready to go.
But that’s not how scrum works. Organizations are used to being able to dictate schedules for large releases of software all at once (via waterfall), and making dev deliver on those schedules. If you’re scheduling a featureset six months out, it’s almost guaranteed you’re not delivering in an agile manner.
So how do we fix scrum?That's not REAL waterfall, it's just a babbling brook on a hill.
The Game is a mind game in which the objective is to avoid thinking about The Game itself. Thinking about The Game constitutes a loss, which must be announced each time it occurs.
The programming version of The Game has the same rules, but you lose if you think about David Heinemeier Hansson (aka DHH).
And no, I'm not linking to why I lost today.
Broke a four-month winning streak, dangit.

Turning Back
by Katia Rose
It took me a long time to read this book. Not because of the quality (it was softly mesmerizing, to no surprise), but because it's the second in what I assume is to be a trilogy. I kept seeing it in my TBR pile and would go to read it, before remembering that, once I finished it, there would only be one more chance to enter this world for the first time. So I put it off.
It was worth the wait.
Katia Rose's remote Vancouver (BC) campground – where these stories take place – even makes me, an avowed inside-only kitty, want to drive out and pitch a tent in the wilderness. Though perhaps there was a touch too much romanticism in the wild's seduction of the main character city girl, it's described with such loving detail that it's impossible not to get swept away.
The characters, as is always the case with Rose, are painstakingly crafted with realistic backstories, baggage, fears and doubts. But even grounded in realism, the sparks between the two main characters (Kennedy and Trish) are more than enough to convince of the romance catching hold, sweeping them away.
I thoroughly enjoyed this book, and wait with some trepidation for the last entry. It can't come soon enough and yet, I know, I'll have to wait to read it.
Almost enough to make me want to visit Canada. Almost. (j/k I love British Columbia, and no other provinces.)
NAIA approves transgender policy limiting women's sports to some athletes | AP News
I can't explain how this feels.
Athletics bans don't affect me, personally, in terms of preventing me from playing sports - I'm well beyond the age or ability for it to matter.
But that fact doesn't make it feel any less like another punch to the head, another hit to the gut, another in a long line of kicks when I already feel so beaten down.
I can't explain this feeling.
It's yet another way of being told that we're different, separate from, less than. Trans women are women except. Trans men are men but.
It's especially disheartening when so many struggle to have even the basic aspects of their dignity respected (names, pronouns, getting an education, not getting fired for existing while trans). Time and again, the only concrete actions taken are to strip more from us.
I can't feel.
It's a systematic desecration of our humanity, a systemic approach to telling us not only do we not belong, but that we shouldn't exist.
A cistem built on our destruction.
I can't.
I desperately want to avoid talking about the (junk) science of it all. I'm putting the finishing touches on a conference talk about properly being data-driven - so many people take whatever (bad) available data they have and try to map it to outcomes that are only loosely correlated. This is a prime example.
If the concern is the effects of testosterone on performance, then organize your damn divisions among testosterone blood counts. Period.
A little living room music
Beyond “clean” code: Focusing on practical (vs. aesthetic) aspects
I grew up on Clean Code, both the book and the concept. I strove for my code to be “clean,” and it was the standard against which I measured myself.
And I don’t think I was alone! Many of the programmers I’ve gotten to know over the years took a similar trajectory, venerating CC along with Code Complete and Pragmatic Programmer as the books everyone should read.
But along the way, “clean” started to take on a new meaning. It’s not just from the context of code, either; whether in interior design or architecture or print design, “clean” started to arise as a synonym for “minimalism.”
I wanted to find an approach, a rubric, that allowed for more specificity. When I get feedback, I much prefer hearing the specific aspects that are being praised or need work on - someone telling me “that code’s clean” or not isn’t particularly actionable.
We call it CPM nowIt is definitely TL, but if I had to W it, you have to R it. Or just come to one of my talks!
When I gave my talk, "That's not real scrum: Measuring and managing productivity for development teams" at MiTechCon 2024 in Pontiac, MI, there were a number of great questions, both in-person and from the app. I collected them here, as a supplement to the accessible version of the talk.
Q: What are best practices on implementing agile concepts for enterprise technology teams that are not app dev (e.g., DevOps, Cloud, DBA, etc.)?
A brief summary: 1) Define your client (often not the software's end-user; could be another internal group), and 2) find the way to release iteratively to provide them value. This often requires overcoming entrenched models of request/delivery — similar to how development tends to be viewed as a "service provider" who gets handed a list of features to develop, I would imagine a lot of teams trying to make that transition are viewed as providers and expected to just do what they're told. Working back the request cycle with the appropriate "client" to figure out how to deliver incremental/iterative value is how you can deliver successfully with agile!
Q: How do I convince a client who wants stuff at a certain time to trust the agile process?
There's no inherent conflict between a fixed-cost SOW and scrum process. The tension that tends to exist in these situations is not the cost structure, but rather what is promised to be delivered and when. Problems ensue when you're delivering a fixed set of requirements by a certain date - you can certainly do that work in a somewhat agile fashion and gain some of the benefits, but you're ultimately setting yourself up to experience tension as you get feedback through iterations that might ultimately diverge from the original requirements.
This is the "change order hell" that often comes with client work — agile is by definition flexible in its results, so if we try to prescribe them ahead of time, we're setting ourselves up for headaches. That's not to say it's not worth doing (the process may be beneficial to the people doing the work if the waterfall outcome is prescribed), but note (to yourself and the client) that a waterfall outcome (fixed set of features at a fixed date) brings with it waterfall risk, even if you do the work in an agile fashion.
It is unfortunately very often difficult, but this is part of the "organizational shift" I spoke about. If the sales team does not sell based on agile output, it's very difficult to perform proper agile development in order the reap all its benefits.
Q: We're using Agile well; How do we dissuade skip-level leadership from demanding waterfall delivery dates using agile processes?
This is very similar to the previous answer, with the caveat that it's not on you to convince a level of leadership beyond your own manager of anything. You can and should be providing your manager with the information and advice mentioned in the above answer, but ultimately that convincing has to come from the people they manage, not levels removed. Scrum (and agile, generally) requires buy-in up and down the corporate stack.
Q: What are best practices for ownership of the product backlog?
Best practices are contextual! Ownership of the product backlog is such a tricky question.
In general, I think product backlogs tend to have too many items. I am very much a fan of expiring backlog items — if they haven't been worked on in 30 days (two-ish sprints), they go away (system-enforced!) until the problem they address comes up again.
The product owner is accountable for the priority and what's included or removed from the product backlog.
I kind of think teams should have two separate stores of stories: One is the backlog, specific ideas or stories that are going to be worked on (as above) in the next sprint or two), which is the product owner's responsibility. The second is a brainstorming pool — preferably not even in the same system (because it is NOT the case that you should be just be plucking from the pool and plopping on the backlog). Rather, these are just broad ideas or needs we want to capture so we don't lose sight of them, but from them, specific problems are identified and stories written. This should be curated by the product owner, but allow for easier/broader access to add to it.
Q: Is it ever recommended to have the Scrum Master also be Product Manager?
(I am assuming for the sake of this question that Product Manager = Product Owner. If I am mistaken, apologies!)
I would generally not recommend the product owner and the scrum master be the same person, though I am aware by necessity it sometimes happens. It takes a lot of varied skills to do both of those jobs, and in most cases if it happens successfully it's because there's a separate system in place to compensate in one or both areas. (e.g., there's a separate engineering manager who's picking up a lot of what would generally be SM work, or the product owner is in name only because someone else/external is doing the requirements- gathering/customer interaction). Both positions require a TON of work to perform properly - direct customer interaction, focus groups, metrics analysis and stakeholder interaction are just some of a PM's duties, while the SM should be devoted to the dev team to make sure any blocks get cleared and work continues apace.
But even more than time, there's a philosophical divide that would be difficult to resolve in one person. The SM should be looking at things from a perspective of what's possible now, whereas the PM should have a longer-term view of what should be happening soon. Rare is the individual who can hold both of those things in their head with equal weight; usually one is going to be prioritized over the other, to the detriment of the process overall.
Q: What is the best (highest paying) Scrum certification?
If your pay is directly correlated with the specific certification you have, you are very likely working for the company that provides it. Specific certifications may be more favored in certain industries or verticals, but that's no more than generally indicative of pay than the difference between any two different companies.
More broadly, I view certifications as proof of knowledge that should be useful and transferable regardless of specific situation. Much like Agile, delivering value (and a track record of doing same) is the best route to long-term career success (and hence more money).
Q: Can you use an agile scrum approach without a central staffing resource database?
Yes, with a but! You do not need a formal method of tracking your resourcing, but the scrum master (at the team level) needs to know their resourcing (in terms of how many developers are going to be available to work that sprint) in order to properly plan the sprint. If someone is taking a vacation, you need to either a) pull in fewer stories, b) increase your sprint length, or c) pull in additional resources (if availble to you).
Even at the story level, this matters. If you have a backend ticket and your one BE developer is out, you're not gonna want to put that in the sprint. But it doesn't need to be a formal, centralized database. It could be as simple as everyone noting their PTO during sprint planning.
What's always both heartening and a little bit sad to me is how much the scrum teams want to produce good products, provide value, and it's over-management that holds them back from doing so.
I keep seeing the iPhone’s popularity and sales numbers thrown around as proto-defenses against allegations of flexing monopolistic power in one category to dominate others.
“Popularity” is an argument IN FAVOR of the the government, not a defense. The argument is that the iPhone is very popular and sold a lot, and Apple is using that position of strength to stifle innovation and hamper the growth of competitors in related categories (payments, apps, music services, etc.).
You can disagree with the suit all you want, just know what you’re arguing for and against.
I think this ultimately traces back to a weird implicit belief I’ve been noticing lately, which is like a Constitutional (or god-given) right to a certain business model. If you listen in the news, you can hear it being implied all the time.
Intersectiona11y: AI, accessibility and the future of work
Solutions come in all sizes. The problem in tech (and many other industries, I presume) is that our processes and workflows are structured in such a way that the solutions for a given problem tend to be clustered around the smaller side of the scale.
Small issues have small solutions. The problem is when you don’t step back and take a bigger-picture view of the situation - do all of these disparate problems actually stem from a particular source? Very often, developers are not only encouraged but actually mandated to stick to whatever story they’re on, for fear of going out of scope.
While that might make sense from a top-down control perspective, that style of thinking tends to permeate a lot of the other work that gets done, even up to larger-scale issues. Diversity is left to HR, or to a diversity committee, to take care of. In many cases, how and where to include AI in an application is left up to individual departments or teams. Remote work, a topic extremely divisive of late, is being eliminated or limited left up to “manager discretion” rather than actually looking at the benefits and harms that are associated with it. A cause extremely close to my heart, accessibility, is frequently treated as an add-on or left up to a handful of specialists to implement (or, worse, a third-party plugin).
These things not only don’t have to, they shouldn’t be left up to small groups to implement or reason through. They should be baked-in to how your organization makes decisions, builds software and interacts with its people.
Learn about the holistic approachI will begrudgingly admit that a 5,000+ word essay is not the most accessible form of this content for everyone. Guess you should just come to one of my talks!
OK, we need to talk about OREOs ... and how they impacted my view of product iteration.
(Sometimes I hate being a software developer.)

I'm sure you've seen the Cambrian explosion of Oreo flavors, the outer limits of which were brought home to me with Space Dunks - combining Oreos with Pop Rocks. (And yes, your mouth does fizz after eating them.)
Putting aside the wisdom or sanity of whoever dreamt up the idea in the first place, it's clear that Oreo is innovating on its tried-and-true concept – but doing so without killing off its premier product. There is certainly some cannibalization of sales going on, but ultimately it doesn't matter to Nabisco because a) regular Oreos are popular enough that you'll never kill them off completely, and b) halo effect (your mom might really love PB oreos but your kid hates them, so you now you buy two bags instead of one!)
In software, we're taught that the innovator's dilemma tends to occur when you're unwilling to sacrifice your big moneymaker in favor of something new, and someone else without that baggage comes along eats your cookies/lunch.
Why can't you do both?
There are a number of different strategies you could employ, from a backend-compatible but disparate frontend offering (maybe with fewer features at a cheaper cost, or radically new UX). What about a faux startup with a small team and resources who can iterate on new ideas until they find what the market wants?
But the basic idea remains the same: Keep working away at the product that's keeping you in the black, but don't exclude experimentation and trying new approaches from your toolkit. Worst-case scenario, you still have the old workhorse powering through. In most cases, you'll have some tepid-to-mild hits that diversify your revenue stream (and potentially eat at the profit margins of your competitors) and open new opportunities for growth.
And every once in a while you'll strike gold, with a brand-new product that people love and might even supplant your tried-and-true Ol' Faithful.
The trick then is to not stop the ride, and keep rolling that innovation payoff over into the next new idea.
Just maybe leave Pop Rocks out of it.
I had the Platonic ideal of peanut butter pies at my wife's graduate school graduation in Hershey, PA, like five years ago. (They were legit Reese's Peanut Butter Pies from Mr. Reese himself.) I've chased that high for years, but never found it again. The peanut butter pie Oreos were probably the closest I've gotten.
If you rush and don’t consider how it is deployed, and how it helps your engineers grow, you risk degrading your engineering talent over time
—Angus Allan, senior product manager at xDesign
I don't disagree that overreliance on AI could stymie overall growth of devs, but we've had a form of this problem for years.
I met plenty of devs pre-AI who didn't understand anything other than how to do the basics in the JS framework of the week.
It's ultimately up to the individual dev to decide how deep they want their skills to go.
AI is not magic, part 1033: Accessibility
You know it's a good sign when the first thing I do after finishing an article is double-check whether the whole site is some sort of AI-generated spoof. The answer on this one was closer than you might like, but I do think it's genuine.
Jakob Nielsen, UX expert, has apparently gone and swallowed the AI hype by unhinging his jaw, if the overall subjects of his Substack are to be believed. And that's fine, people can have hobbies, but the man's opinions are now coming after one of my passions, accessibility, and that cannot stand.
Get mad with me"I always love quoting myself." - Kait
We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control.
—Automattic, trying to backpedal after triumphantly announcing they got someone to pay them for their users' content
Oh yeah, all those AI companies that definitely care about attribution.
Between this and the Tumblr moderation nonsense, really seems like Matty is doing the dickish tech CEO speedrun. A modern-day Jason Russell.
Your frontend is not your backend: Using data transfer objects to keep your code focused
Today I want to talk about data transfer objects, a software pattern you can use to keep your code better structured and metaphorically coherent. It’s a tool that can help you stay in the logical flow of your application, making it easier to puzzle through and communicate about the code you’re writing, both to yourself and others.
The DTO is one of my go-to patterns, and I regularly implement it for both internal and external use.
I’m also aware most people already know what pure data objects are. I’m not pretending we’re inventing the wheel here - the value comes in how they’re applied, systematically.
🎵 I got a DTOooooo
Sexism in tech is alive and well
Honestly, I thought we were past this as an industry? But my experience at Developer Week 2024 showed me there's still a long way to go to overcoming sexism in tech.
And it came from the source I least expected; literally people who were at the conference trying to convince others to buy their product. People for whom connecting and educating is literally their job.
Time and again, both I (an engineer) and my nonbinary wife (a business analyst, at a different organization) found that the majority of the masculine-presenting folks at the booths on the expo floor were dismissive and disinterested, and usually patronizing.
Hear the tale as old as timeAlso, the sheer number of static code analysis companies makes me thinks there's a consolidation incoming. Not a single one of three could differentiate their offerings on more than name and price.
“[Random AI] defines ...” has already started to replace “Webster’s defines ...” as the worst lede for stories and presentations.
I let the AI interview in the playbill slide because the play was about AI, but otherwise, no bueno.
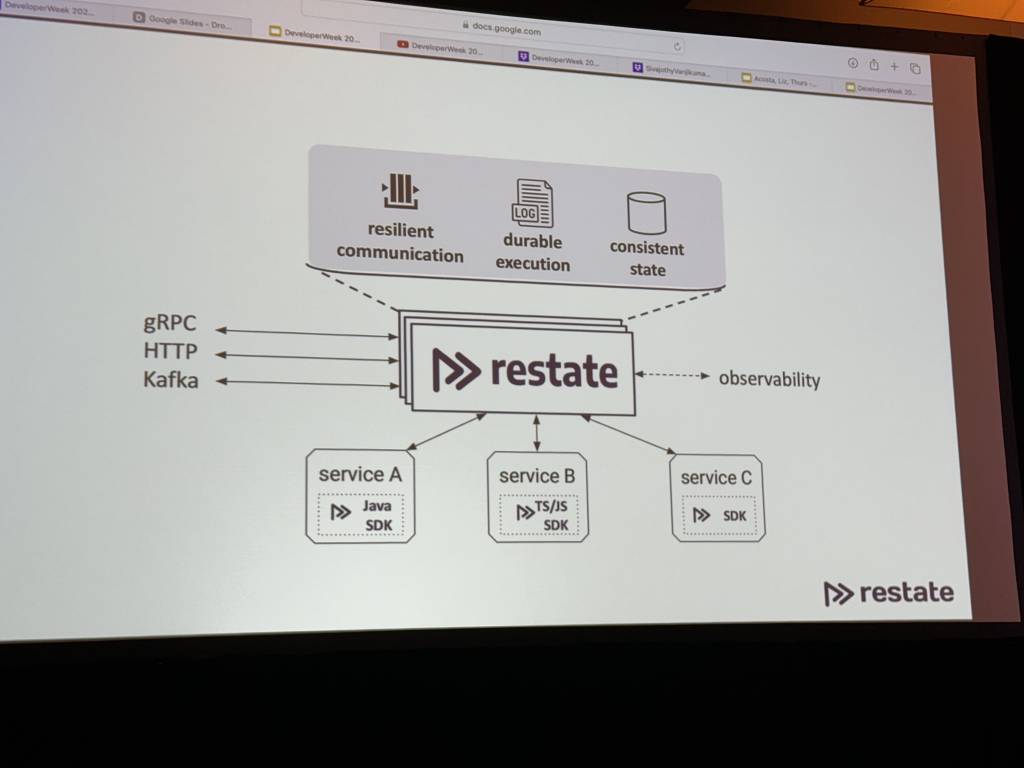
The way to guarantee durability and failure recovery in serverless orchestration and coordination is … a server and database in the middle of your microservices.
I’m sure it’s a great product, but come on.
I have previously mentioned that I love NextDNS, but they do not make certain fundamental things, like managing your block and allow lists, very easy. Quite often I'll hit a URL that's blocked that I'd like to see - rather than use their app, I have to load their (completely desktop-oriented) website, navigate to the right tab, then add the URL in.
That's annoying.
Without writing an iOS app all of its own (which sounds like a lot of work), I wanted an easy to way to push URLs to the block or deny list. So I wrote an iOS Shortcut that works with a PHP script to send the appropriate messages.
You can find the shortcut here.
The PHP script can found at this Gist. You'll need to set the token, API key (API key can be found at the bottom of your NextDNS profile) and profile ID variables in the script. The token is what you'll use to secure your requests from your phone to the server.
I thought about offering a generic PHP server that required you to set everything in Shortcuts, but that's inherently insecure for everyone using it, so I decided against it. I think it would be possible to do this all in Shortcuts, but Shortcuts drives me nuts for anything remotely complex, and this does what I need it to.
It really is annoying how hard it is to manage a basic function. NextDNS also doesn't seem to have set their CORS headers properly for OPTIONS requests, which are required for browser-based interactions because of how they dictated the API token has to be sent.
OpenAI announced Sora, a new model for text-to-video, and it's ... fine? I guess? I mean, I know why they announced it - it's legitimately really cool you can type something in and a video vaguely approximating your description in really high resolution shows up.
I just don't think it's really all that useful in real-world contexts.
Don't get me wrong, I appreciate their candor in the "whoopsies" segments, but even in the show-off pieces some of the video is weird to just downright bad.
 Hands are hard! I get it! But there's also quite literally a "bag lady" (a woman who appears to be carrying at least two gigantic purses), and (especially when the camera moves) the main character floats along the ground without actually walking pretty often.
Hands are hard! I get it! But there's also quite literally a "bag lady" (a woman who appears to be carrying at least two gigantic purses), and (especially when the camera moves) the main character floats along the ground without actually walking pretty often.
Are these nitpicky things people aren't going to notice on first glance? Maybe. But remember the outrage around Ugly Sonic? People notice small (or large) discrepancies in their popular entertainment, and the brand suffers for it. To say nothing of advertisers! Imagine trying to market your brand-new (well, "new" in car definitions) car without an accurate model of said car in the ad. Or maybe you really want to buy the latest Danover.
 It seems like all the current AI output has a limit of "close-ish" for things, from self-driving to video to photos to even text generation. It all requires human editing, often significant for any work of reasonable size, to pull it out of the uncanny valley.
It seems like all the current AI output has a limit of "close-ish" for things, from self-driving to video to photos to even text generation. It all requires human editing, often significant for any work of reasonable size, to pull it out of the uncanny valley.
"But look how far they've gotten in such little time!" they cry. "Just wait!"
But nobody's managed to push past that last 10% in any domain. It always requires a human touch to get it "right."
Like the fake Land Rover commercial is interesting, except imagine the difficulty of getting it to match your new product (look and name) exactly. You're almost going to have to CGI it in after, at least parts, at which point you've lost much of the benefit.
Unfortunately, "close enough" is good enough for a lot of people who are lazy, cheap or don't care about quality. The software example I'd give is there probably aren't a lot of companies who'd be willing to pay for software consultant services who are just going to use AI instead, but plenty of those people who message you on LinkedIn willing to pay you $200 for a Facebook clone absolutely are going to pay Copilot $20 a month instead.
And yes, there will be those people (especially levels removed from the actual work) who will think they can replace their employees with chatbots, and it might even work for a little bit. But poorly designed systems always have failure points, and once you hit it you're going to wind up having to scrap the whole thing. A building with a bad foundation can't be fixed through patching.
I have a feeling it's the same in other industries. I do think workers will feel the hit, especially on lower-budget products already or where people see an opportunity to cut corners. I also think our standards as a society will be relaxed a little bit in a lot of areas, simply because the mean will regress
But in good news, I think this'll shake out in a few years where people realize AI isn't replacing everything any more than Web3 did, but AI will have more utility as a tool in the toolkit of professionals. It's just gonna take a bit to get there.
The funny thing is a lot of the uncanny stuff makes it look like the model was trained on CGI videos, which might be a corollary to the prophesied problem of AI training on AI outputs. The dalmatian looks and moves CGI af, and the train looks like a bad photoshop insert where they had a video of a train on flat ground and matted over the background with a picture.
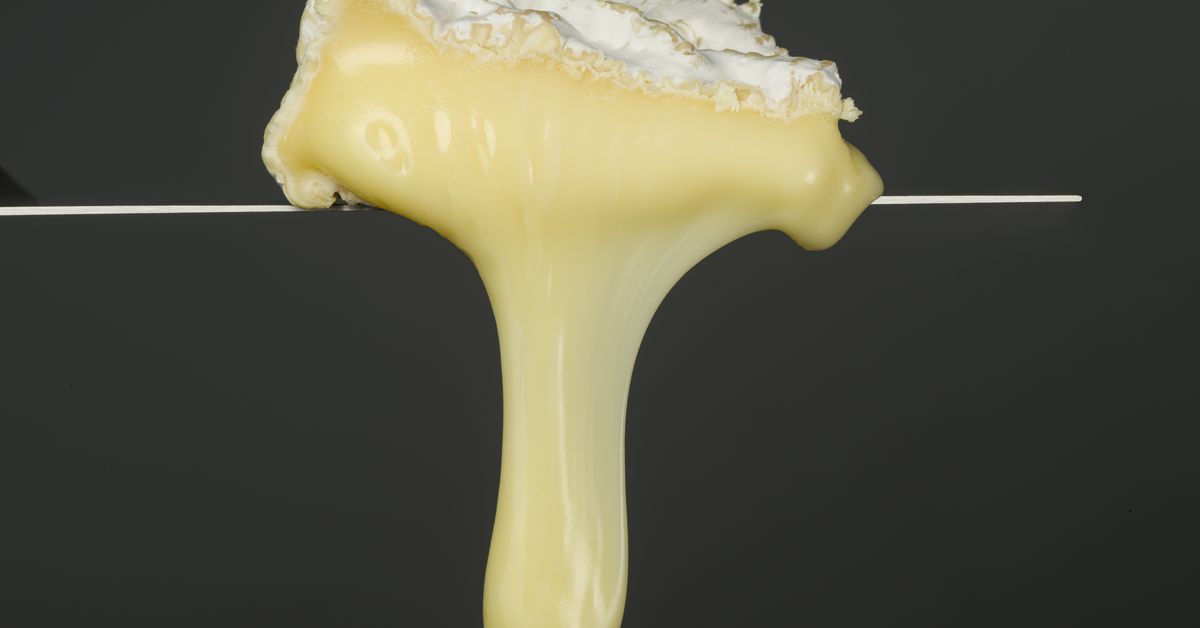
These delicious French cheeses could disappear, scientists warn - Vox
Gird your curds! Say a prayer for Camembert! A collapse in microbe diversity puts these French cheeses at risk.
An interesting unexpected side effect of uniformity in food (which I generally like!).